[mathjax]前の投稿「ニューラルネットワークの基本」に引き続き、バックプロパゲーション(逆伝播)を用いて、重みパラメータとバイアスパラメータを導出する方法について解説します。
最も基本的なニューラルネットワークとして、図1の入力層、隠れ層、出力層で構成された3層構造を考えます(入力層は非線形関数を持たず、ただ入力するだけなので、層としてカウントせず、これを2層構造と言う人もいる)。
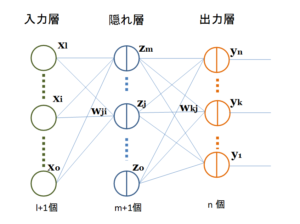
図1.基本的なニューラルネットワークのモデル
〇は非線形活性化関数を持たないユニットを、縦線のある①はこれを持つユニットを表す
入力層の入力データ\(x_i\)の数を \(l\)個、出力データ\(y_k\)数を\(n\)個とすると、入力層と出力層のユニット数は各々 \(l+1\)個、\(n\)個となります。、隠れ層のユニット数は任意に設定することができますが、ここでは\(m+1\)個とします。入力層と隠れ層のユニット数に+1があるのは、バイアスパラメータを意味しています。
また、出力データ\(y_k\)に対応する正解データ\(T_k\)を準備する必要があります。正解データは教師データと呼ばれ、機械学習の結果、出力データを到達させる目標点となります。
それでは、ニューラルネットワークのパラメータ(結合荷重)を計算する方法を説明します。
まず、入力層に入力されたデータ\(x_i\)と隠れ層への入力値\(a_j\)、出力値\(z_j\)と出力層への入力値\(b_k\)、出力値\(y_k\)の間には、前の投稿の式(3)から、次式が得られます。
\[\begin{eqnarray*}
a_j&=&\sum_{i=1}^{l} w_{ji} x_i +w_{j0} \qquad (1)\\
\\z_j&=&f( a_j) \qquad \qquad \qquad (2)\\
\\b_k&=& \sum_{j=1}^{m} w_{kj} z_j +w_{k0} \qquad (3)\\
\\y_k&=&g( b_k) \qquad \qquad \qquad (4)
\end{eqnarray*}\]
ここで、\(f()\)、\(g()\)、\(w_{ji}\)、\(w_{kj}\)は隠れ層と出力層の非線形活性化関数と結合荷重(重みパラメータとバイアスパラメータ)を表しています。\(w_{ji}\)は隠れ層 j 番目のユニットと入力層 i 番目のユニットをつなぐ荷重結合で、\(w_{kj}\)は出力層 k 番目のユニットと隠れ層 j 番目のユニットをつなぐ結合荷重です。
非線形活性化関数として、シグモイド関数やハイパボリックタンジェント関数、Softmax関数が用いられるので、文末にそれらの関数と微分形を整理しておきます。
さて、入力データと正解データからパラメータを算出する目的は、出力値\(y_k\)を教師データ\(T_k\)に近づけることです。従って、出力値\(y_k\)と教師データ\(T_k\)との乖離を示す二乗誤差Eを最少にする結合荷重\(w_{ji}\)、\(w_{kj}\)を求めます。
\[E=\frac { 1 }{ 2 } \sum _{ k=1 }^{ n }{ { \left( { y }_{ k }-{ T }_{ k }\right)}^{ 2 }} \qquad (5)\]
先ず最初に、出力層と隠れ層をつなぐ結合荷重\(w_{kj}\)を、学習率ηを用いて求めます。1回の学習における微小更新量\(\Delta w_{kj}\)を次式のように設定します。
\[\Delta { w }_{ kj }=-\eta \frac {\partial E}{ \partial { w }_{ kj }}\qquad (6)\]
式(6)は一見どのように導出されたのか不思議に思われるかもしれないが、これはただ単に荷重結合\(w_{kj}\)が誤差Eに与える影響∂E/∂\(w_{kj}\)に対し、学習率ηで、Eが小さくなる方向に(-符号をつけて)\(w_{kj}\)を更新する、ということを意味しているに過ぎません。
式(6)は連鎖則(chain rule)により次式のように書くことができます。
\[\Delta { w }_{ kj }=-\eta \frac { \partial E }{ \partial {y}_{k}} \frac { \partial {y}_{k}}{ \partial { b}_{ k } } \frac { \partial { b}_{ k } }{ \partial { w }_{ kj } }\qquad (7)\]
式(7)の各項を見ていきましょう。
式(5)より
\[\frac { \partial E }{ \partial {y}_{k}}=\left( {y}_{k}-{ T }_{ k } \right)\qquad (8)\]
式(4)より
\[\frac { \partial { y }_{ k } }{ \partial { b }_{ k } } =\frac { \partial g\left( { b }_{ k } \right)}{ \partial { b }_{ k } } =g^{ \prime }\left( { b }_{ k } \right) \qquad (9)\]
式(3)より
\[\frac { \partial { b }_{ k } }{ \partial { w }_{ kj } } =\frac { \partial \sum _{ k=1 }^{n}{{w}_{ kj}{ z}_{j}}}{ \partial { w }_{ kj }}={z}_{j}\qquad (10)\]
よって、式(8)、(9)、(10)を用いることで、荷重結合の更新量は次式で表されます。
\[\begin{eqnarray*}\Delta {w}_{kj}&=&-\eta\left({y}_{k}-{T}_{k}\right)g^{\prime}\left({b}_{k}\right)z_j\qquad(11)\\ \\&=&-\eta{\delta}_{k}z_j\qquad(12)\end{eqnarray*}\]
ここで、\(\delta_k = (y_k-T_k)g'(b_k)\)と置き換えています。
以上のように、結合荷重の更新量は式(12)で表されるので、p回学習した結合荷重を\(w_{kj}^p\)で表すと
\[{ w }_{ kj }^{ p+1 }={ w }_{ kj }^{ p }+\Delta { w }_{ kj}\qquad (13)\]
となります。出力\(y_k\)が教師データ\(T_k\)に近づくと、式(11)の荷重結合の更新量も小さくなり、収束に向かうことが分かります。
次に、隠れ層と入力層の間の荷重結合の微小更新量\(\Delta w_{ji}\)を式(6)と同様に設定します。
\[\Delta { w }_{ ji }=-\eta \frac {\partial E}{ \partial { w }_{ ji }}\qquad (14)\]
隠れ層からの出力\(z_j\)は出力層の全てのユニットに広がって連結された後に、誤差Eに影響するために、連鎖則(Chain Rule)では、連結されている全てのユニットを考慮して、式(14)は次式のように展開します。
\[\begin{eqnarray*}\Delta { w }_{ ji }&=&-\eta \frac { \partial E}{ \partial { z }_{ j } }\frac { \partial { z }_{ j } }{ \partial { a }_{ j } } \frac { \partial { a }_{ j } }{ \partial { w }_{ ji } }\\ \\&=&-\eta \frac { \partial \left\{ \sum _{ k=1 }^{ n }{ { E }}\right\} }{ \partial { z }_{ j } }\frac { \partial { z }_{ j } }{ \partial { a }_{ j } } \frac { \partial { a }_{ j } }{ \partial { w }_{ ji } }\\ \\&=&-\eta \left\{ \sum _{ k=1 }^{ n }{ \frac { \partial E }{ \partial { z }_{ j } }}\right\} \frac { \partial { z }_{ j } }{ \partial { a }_{ j } } \frac { \partial { a }_{ j } }{ \partial { w }_{ ji } }\qquad (15)\\ \\&=&-\eta \left\{ \sum _{ k=1 }^{ n }{ \frac { \partial E }{ \partial { y }_{ j }}\frac { \partial { y }_{ j } }{ \partial { b }_{ j } } \frac { \partial { b }_{ j }}{ \partial { z }_{ j } }}\right\} \frac { \partial { z }_{ j } }{ \partial { a }_{ j } } \frac { \partial { a }_{ j } }{ \partial { w }_{ ji } } \qquad (16)\end{eqnarray*}\]
式(16)の各項を見ていきます。
式(8)より、\(\partial E/\partial y_k\)が、式(9)より、\(\partial y_k/\partial b_k\)が得られ、また
\[\frac { \partial { b }_{ k } }{ \partial { z }_{ j }} =\frac { \partial \sum _{ k=1 }^{ n }{{w}_{ kj }{z}_{k}}}{ \partial {z}_{j}}={w}_{ kj }\qquad (17)\]
となる。式(2)より
\[\frac { \partial { z }_{ j } }{ \partial { a }_{ j } } =\frac { \partial f\left( { a }_{ j } \right)}{ \partial { a }_{ j } } =f^{ \prime }\left( { a }_{ j } \right)\qquad (18)\]
となり、式(16)の最後の項は
\[\frac { \partial { a }_{ j } }{ \partial { w }_{ ji } } =\frac { \partial \sum _{ i=1 }^{ l }{ { w }_{ ji }{ x }_{ i } }}{ \partial { w }_{ ji } } ={ x }_{ i }\qquad (19)\]
となる。よって
\[\Delta { w }_{ ji }=-\eta \left\{ \sum _{ k=1 }^{ n }{ \left( { y }_{ k }-{ T }_{ k } \right) g^{\prime}\left( { b }_{ k } \right) { w }_{ kj } } \right\} f^{ \prime }\left( { z }_{ j } \right) { x }_{ i }\qquad (20)\\ =-\eta \left\{ \sum _{ k=1 }^{ n }{ { w }_{ kj }{ \delta}_{k}}\right\} f^{\prime}\left( { z }_{ j } \right) { x }_{ i }\qquad (21)\]
\[ =-\eta { \delta}_{j}{ x }_{ i }\qquad (22)\]
のように荷重結合の更新量が得られました。ただし、ここでは次式を利用しています。
\[{ \delta }_{ j }=f^{ \prime }\left( { z }_{ j } \right) \sum _{ k=1 }^{ n }{ { w }_{ kj }{ \delta}_{ k } } \qquad (23)\]
従って、式(13)と同様に、p回の更新によって、入力層と隠れ層の間の荷重結合\(w_{ji}^p\)は、次式のように表されます。
\[{ w }_{ ji }^{ p+1 }={ w }_{ ji }^{ p }+\Delta { w }_{ ji }\qquad (24)\]
式(13)と合わせると、全ての結合荷重が算出できました。これがニューラルネットワークの誤差逆伝播で行うパラメータ更新の内容です。
多くのデータを用いて学習させ、結合荷重を収束させて、決定することが出来たならば、それを用いてニューラルネットワークの式(1)~(4)を構築します。そして、新たな入力データに対してフィードフォワードの計算することで、簡単に出力を得ることができます。その出力は、新たな入力データを過去データに基づいて判断した答えというになります。
ただ、学習用のデータセットに対しては式(5)の誤差Eが局所的極小点(Local Minimum)に落ち込み比較的小さい値を示すものの、その後の新規データに対してはEの値が大きく、結果がよくないことがしばしば起こります。これを過学習(overfitting)と言います。この過学習を防ぐための工夫について、次回お話します。
---------------------------
<お勧め書籍>
機械学習について丁寧に書かれた良書です。本格的に勉強したい人には必携のお勧め本です。
良書の紹介:機械学習の理解を深めるには良い本です
======== 非線形活性化関数 ========
シグモイド関数
\[h\left( x \right) =\frac { 1 }{ 1+exp\left( -x \right)}\qquad (a1)\]
\[\frac { \partial h\left( x \right)}{ \partial x } =h\left( x \right) \left( 1-h\left( x \right) \right) \qquad (a2)\]
ハイパボリックタンジェント関数
\[h\left( { x } \right) =tanh\left( x \right)=\frac { exp\left( x \right) -exp\left( -x \right)}{ exp\left( x \right) +exp\left( -x \right)}\qquad (a3)\]
\[\frac { \partial h\left( x \right)}{ \partial x } =1-h\left( x \right) \cdot h\left( x \right)\qquad (a4)\]
Softmax関数
\[h\left( { x } \right) =\frac { exp\left( { x }_{ i } \right)}{ \sum _{ j=1 }^{ n }{ exp\left( { x }_{ j } \right)}}\qquad (a5)\]
\[\frac { \partial h\left( { { x }_{ i } } \right)}{ \partial { x }_{ i } } =h\left( { x }_{ i } \right) \qquad (a6)\]
Softmax関数はその層にある全ユニットの出力値の合計を分母とし、注目ユニットの出力を分子に持っています。これは全てのユニットの出力合計を1に規格化するためであり、出力を確率に変換する際などに利用されます。
「ニューラルネットワークの誤差逆伝播式(バックプロパゲーション)」への4件の返信
式(22)の中のXi(前層のi番目のユニット出力)は、学習する教師データの数(n個)だけ存在しますが、この式による結合荷重の更新は、どの出力を用いれば良いのでしょうか?
バッチ処理の場合は教師データn個に対して結合荷重を1回更新するので、n個の出力の平均値を用います。
これに対して教師データ1個に対して結合荷重を1回更新する場合は、1個の出力を用います。これはバッチ処理の教師データの数を1個にした事と同じになります。
ユニットの出力を平均することに数学的な意味があるのでしょうか?
加えて、教師データ1個に対する荷重更新に学習の意味があるのでしょうか?
先ず、「教師データ1個に対する荷重更新に学習の意味があるのでしょうか」に対する回答ですが
誤差逆伝播式は教師データ1個の出力に対する誤差を逆伝播させる基本形を想定しています。通常、教師データは多数あり、逆伝播を多数回行って学習を進めています。
「ユニットの出力を平均化する」のは、1個のデータで1回逆伝播させて学習させると、データのバラツキがそのまま学習に反映されて収束しにくいことがよくあります。そこでバッチ処理によりデータの平均値をとって個々のデータのバラツキを抑えて収束をしやすくします。