[mathjax]強化学習が世間の注目を集めるようになったのは、2016年3月に人工知能のアルファ―碁が囲碁の世界チャンピオンを破ってからであろう。囲碁はチェスや将棋などに比べて碁盤のマス目が多く、差し手の選択肢の広がりが膨大で、当分は人間に勝てないだろう、と言われていた。しかし、この予想をくつがえし、強化学習にディープラーニングを適用したアルファ碁は人間の世界チャンピオンを破った。その後もさらに進化し、2016年の年末には世界のトッププロを相手に60戦無敗という圧倒的な強さを示した。とうとう人工知能はここまで到達したのだ。もはや強化学習を知らずして人工知能を語ることはできない。
迷路脱出プログラム(強化学習)
さて、機械学習は大きく分けると、教師あり学習、教師なし学習、強化学習に分類される。この詳細については以前の投稿を参考にして頂きたいが、強化学習はその時点での正解は分からないが、最終的な正解や狙いは分かっている場合に適用される機械学習法である。囲碁の場合も対局の途中では本当の正解の布石はほとんど分からないが、最終的な正解は明確で相手より広い陣地(石で囲んだ範囲)を取ることだ。
この最終的な目的を達成するために、強化学習ではある環境の中にいるエージェント(対象物)を想定する。環境はある「状態」にあり、そこでエージェントはある方策(Policy)に基づいて「行動」をとる。その行動により「状態」は変化し、その結果エージェントは「報酬」を受け取る。その報酬の大小によりエージェントは目的を達成する「行動」を強化していく、というプロセスをとる。
強化学習の代表的な手法としてQ学習法がある。これは以下の手順で学習する。
- 環境の状態を\(s\)、エージェントの行動を\(a\)、行動価値関数を\(Q(s,a)\)(初期値0)、状態の集合を\(S\)、行動の集合を\(A\)とする。\(\forall s=S, \forall a=A\)と表される。
- エージェントは環境の状態\(s_t\)の中にいる。
- エージェントは確率\(ε\)で行動の集合\(A\)からランダムに行動を選択し、確率\((1-ε)\)で行動価値関数を最大にする\( arg \underset { { a }\in A }{ max } Q({ s_t },{ a })\)の行動を選択する。選択した行動\(a_t\)を実行する。
- 行動\(a_t\)により状態は\(s_{t+1}\)に遷移し、報酬\(r\)を受け取る。
- 学習率\(\alpha\)と割引率\(\gamma\)を用いてQ値を以下のように更新する。
\[\begin{eqnarray*}
Q(s_t,a_t)\leftarrow (1-\alpha )Q(s_t,a_t)+\alpha {\delta}_{t} \qquad (1) \\
{\delta}_{t} \equiv r+\gamma \underset { { a }\in A }{ max } Q({ s_{t+1} },{ a }) \quad\qquad (2)
\end{eqnarray*}\] - 時間ステップ\(t\)を\(t+1\)に進め、手順2から繰り返す。
手順3では、確率\(ε\)でランダムに行動を選択し、確率\(1-ε\)で行動価値関数を最大にする行動を選択している。この方策は\(ε\)-greedy方策と呼ばれており、学習回数の増加とともに\(ε\rightarrow0\)となるようにスケジューリングすれば、行動選択は最適方策に近づいてゆく。
強化学習は応用範囲が非常に広い機械学習法で、囲碁や将棋のみならず、インベーダーゲームや対戦ゲームの操作方法、あるいは自転車の乗り方や二足歩行のバランスの取り方など、様々な分野に応用できる。今後ますます利用が広がりそうなテーマなので、是非とも理解しておきたい項目である。
そこで今回はその手始めとなる迷路脱出のプログラムを上記の手順に基づいて作成した(C++)。それが冒頭のビデオである。学習率\(\alpha=0.5\)、割引率\(\gamma=0.99\)、確率\(ε=0.5\)、学習回数200回(エピソード)、1エピソードでの最大ステップ数は1000とし、そこでスタートに戻り次のエピソードを開始させた。報酬はゴールに入れば10000ポイント、スタートに入れば-100ポイント、その外は全て-1ポイントとした。溝に落ちた場合は落ちる前の位置に戻すだけで、報酬は-1ポイントのままにした。溝に落ちることを防ぐと早くゴールにたどり着くので、そのペナルティはあえて科していない。確率\(ε\)の初期値は0.5としたが、1エピソード毎に0.9を乗じて手順3におけるランダムな行動を徐々に減らし、行動価値関数を最大にする行動を採用するようにした。従って、最初は溝に落ちまくっているが、学習回数が増えるに従い、溝に落ちなくなり、ゴールに早く到達するようになる。ビデオの上端に表示した「EPISODE」は学習回数を表示している。0は初回で、40回の学習毎にビデオ表示するようにした。最後にビデオタイトルが「EPISODE ○○」ではなく「Labyrinth」と表示されるが、これは学習200回を終えた後、テスト走行させた時の様子を示している。
迷路の構造は簡単に変えられるように、下のような配列を用いた。数値4が通路で、数値0は溝、スタート(s)は1、ゴール(G)は3とした。
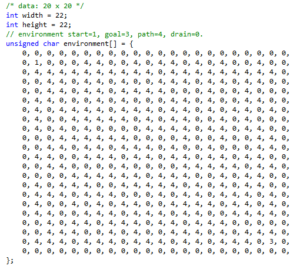
どのような迷路の形を作成しても、着実に学習して全てゴールに辿り着いた。もちろん、スタート点とゴール点が近いと早くゴールに辿り着く。ゴールに到達した時の報酬の値は10000ポイントとしたが、これは10や100、1000にしてもほとんど変わりはなかった。
この迷路脱出のプログラムの動作を見て、私は努力の大切さを思い知らされたような気がした。人間であれば溝に落ち続けてゴールにたどり着けない場合、あきらめて止めてしまうが、コンピュータは延々と脱出口を求めて学習し続けることができる(当たり前だが)。この無限に近い学習過程を取ることが出来る点において、強化学習は秀逸である。