前の投稿ではニューラルネットワークとディープラーニングの構造を比較した。そこでは手書き数字画像(幅28画素*高さ28画素の白黒画像)を認識する場合を取り上げた。今回はその構造の違いにより性能がどのように異なるのかを説明する。
まず、前の投稿で示したニューラルネットワークとディープラーニングの画像認識プログラムをC++言語で作成した。機械学習の理論に基づいて、全てのプログラムを自作した。手書きの数字画像はMNISTのデータベースを使用した。ここには7万画像が含まれているので、トレーニングに6万画像、性能テストに残りの1万画像を使った。トレーニングに使った画像は性能テストには使用しないことが、正しく性能を評価する上で重要である。
図1にニューラルネットワーク(MLP:多層パーセプトロン)の場合のトレーニング回数(Training Epochs)と性能テストの正解率(Correct Rate)の関係を示す。トレーニングにおいては、6万枚の画像からランダムに画像を選び、画像1枚を入力する毎にバックプロパゲーションにて結合荷重を更新した。
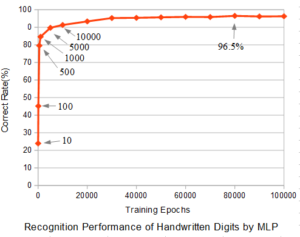
トレーニングパラメータとして学習率ETA=0.01 とした。図中の←10、←100、←500、←1000などはトレーニング回数を表す。認識するのは数字0~9の10文字なので、全くデタラメに回答した場合の正解率は10%となるが、わずか10回学習するだけで、正解率が24%になり、100回で45.2%、1000回で84.6%と急速に向上する。このように正解率が急速に向上するのは、バックプロパゲーションによる学習(結合荷重の更新)が効果的になされていることを示している。
トレーニング1万回では91.3%、3万回で95.4%となり、その後、正解率は横這いとなる。8万回の時に最高値96.5%となっているが、約6万回以降、トレーニング毎の結合荷重の更新で正解率が微小に振動しているので、その影響で最高値が出たと考えられる。トレーニングに使える画像が6万枚であるので、トレーニング回数も6万回程度で飽和するのはもっともなことだと考えられる。トレーニングに使用した画像が似たような画像ばかりであれば、もっと少ないトレーニング回数で正解率が飽和することもあり得る。
次にディープラーニング(CNN:コンボリューショナルニューラルネットワーク)による手書き数字の認識正解率とトレーニング回数のグラフを図2に示す。用いたデータは上記と同じMNISTデータである。
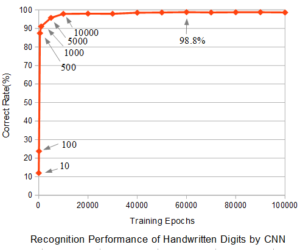
ディープラーニングのトレーニングパラメータとして、学習率ETA=0.01、バッチサイズ10、Momentum=0.1、L2=0.001とした。ドロップアウトは用いていない。バッチサイズ10とは10枚の画像で1回結合荷重を更新することを意味する。
図2でも最初のトレーニングで急速に正解率が向上しており、バックプロパゲーションによる学習が適切に行われていることが分かる。1万回程度のトレーニングで正解率は横這いとなるが、それ以降ほんのわずかずつ向上し、6万回では最高値98.8%の正解率を出した。しかし、このあたりではMLPによるトレーニングと同様に、結合荷重の更新毎に正解率は微小に振動している。また、パラメータの値を変えたり、あるいはCNNの層構造やカーネルのサイズを変えると、正解率も変わるので、いろいろ工夫することで、さらに良い正解率を達成することも十分可能である。
以上のように、従来のニューラルネットワークと最近注目されているディープラーニングの基本的な構造でその性能を比較した。画像認識の性能はそれぞれ96.5%と98.8%となり、2%の差が出た。100%に近いレベルにおいて2%の差が出るということは結構な性能向上と言ってよいであろう。私もこのMNISTのデータを目視で少しだけ認識したが、実は判断のつかない画像が散見された。図3はMNISTデータの一例だが、数字が何なのかを認識するのは簡単ではない。

図3の各数字の右上と右下に小さい数字が記入されているが、右上が正解で右下が間違いの例である。人間でも判断できない数字も少なくない。このような判別が難しい手書き数字の認識において正解率が98.8%あれば、まあま優秀と言えるのではないだろうか。画像認識プログラムは学習データだけを基準として判断するので、人間のような思い込みや自分の癖などが反映されない。よって、人間より客観的な判断ができると言える。
このような画像認識が可能となったディープラーニングは今後益々様々な用途に利用されていくことは間違いなさそうだ。